海外翻墙免费加速器:[入口]
1、由于现在需要做的网站优化越来越多,导致偶尔有的网站出现异常情况,不能及时发现,所以才有了此脚本。
2、主要用于批量获取网站标题,运行此脚本的前提是先要获取批量监测的网址url。
批量获取网页标题脚本:
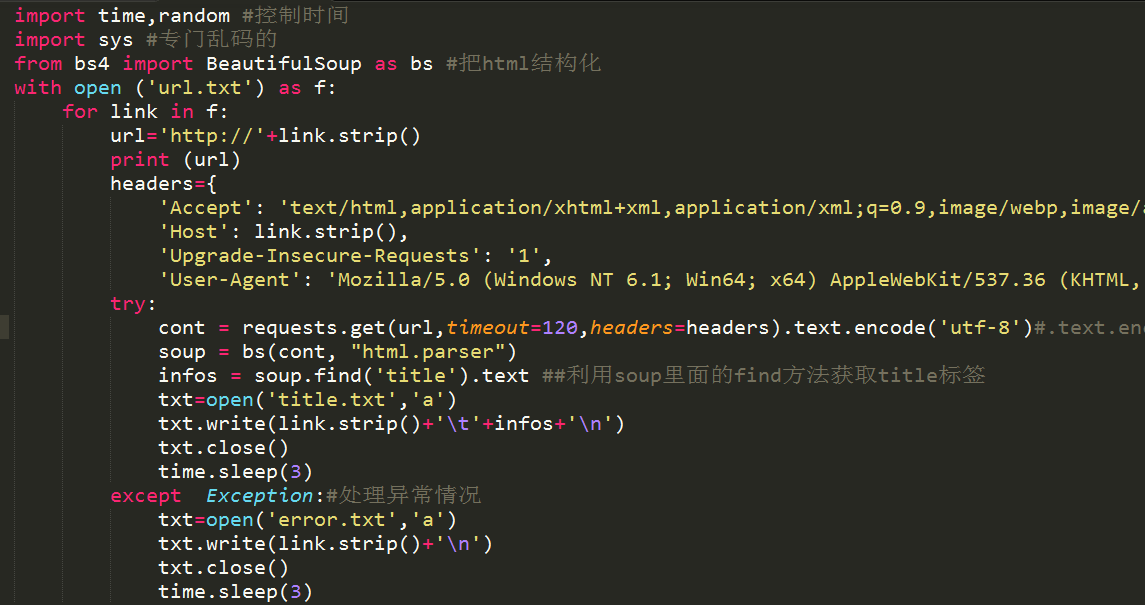
#coding:utf-8
#author:
import requests #打开
import time,random #控制时间
import sys #专门乱码的
from bs4 import BeautifulSoup as bs #把html结构化
with open (‘url.txt’) as f:
for link in f:
url=’http://’+link.strip()
print (url)
headers={
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3’,
‘Host’: link.strip(),
‘Upgrade-Insecure-Requests’: ‘1’,
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36’ }
try:
cont = requests.get(url,timeout=120,headers=headers).text.encode(‘utf-8’)#.text.encode(‘utf-8’)处理GBK乱码问题
soup = bs(cont, “html.parser”)
infos = soup.find(‘title’).text ##利用soup里面的find方法获取title标签
txt=open(‘title.txt’,’a’)
txt.write(link.strip()+’\t’+infos+’\n’)
txt.close()
time.sleep(3)
except Exception:#处理异常情况
txt=open(‘error.txt’,’a’)
txt.write(link.strip()+’\n’)
txt.close()
time.sleep(3)
批量获取网页标题截图:
 ps:脚本如果直接复制粘贴的话会有语法错误,需要自行修改,由于流量限制不放脚本文件下载,如果有这方面需求的可以联系博主本人(ps:有偿)。
ps:脚本如果直接复制粘贴的话会有语法错误,需要自行修改,由于流量限制不放脚本文件下载,如果有这方面需求的可以联系博主本人(ps:有偿)。
未经允许不得转载:陈海飞博客 » python脚本-批量获取网页标题