海外翻墙免费加速器:[入口]
pandas模块是基于NumPy模块的一个开源Python模块,广泛应用于完成数据快速分析、数据清洗和准备等工作,它的名字来源于“panel data”(面板数据)。pandas模块提供了非常直观的数据结构及强大的数据管理和数据处理功能,某种程度上可以把pandas模块看成Python版的Excel。如果是利用Anaconda安装的Python,则自带pandas模块,无须单独安装。
与NumPy模块相比,pandas模块更擅长处理二维数据,其主要有Series和DataFrame两种数据结构。
Series类似于通过NumPy模块创建的一维数组,不同的是Series对象不仅包含数值,还包含一组索引,演示代码如下:
1 import pandas as pd
2 s = pd.Series([‘丁一’, ‘王二’, ‘张三’])
3 print(s)
运行结果如下:
1 0 丁一
2 1 王二
3 2 张三
4 dtype: object
可以看到,s是一个一维数据结构,并且每个元素都有一个可以用来定位的行索引,例如,可以通过s[1]定位到第2个元素’王二’。
Series很少单独使用,我们学习pandas模块主要是为了使用它提供的DataFrame数据结构。
DataFrame是一种二维表格数据结构,可以将其看成一个Excel表格,示例见下表。
一、二维数据表格DataFrame的创建与索引的修改
本节先讲解创建DataFrame的方法,再介绍DataFrame索引的修改。
DataFrame的创建
DataFrame可以通过列表、字典或二维数组创建,下面分别介绍具体方法。
(1)通过列表创建DataFrame
利用pandas模块中的DataFrame()函数可以基于列表创建DataFrame。演示代码如下:
1 import pandas as pd
2 a = pd.DataFrame([[1, 2], [3, 4], [5, 6]])
3 print(a)
运行结果如下:
1 0 1
2 0 1 2
3 1 3 4
4 2 5 6
和之前通过NumPy模块创建的二维数组进行比较:
1 [[1 2]
2 [3 4]
3 [5 6]]
通过比较可以发现,DataFrame更像Excel中的二维表格,它也有行索引和列索引。需要注意的是,这里的索引序号是从0开始的。
我们还可以在创建DataFrame时自定义列索引和行索引,演示代码如下:
1 import pandas as pd
2 a = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=[‘date’, ‘score’],index=[‘A’, ‘B’, ‘C’])
3 print(a)
第2行代码中的参数columns用于指定列索引名称,参数index用于指定行索引名称。运行结果如下:
1 date score
2 A 1 2
3 B 3 4
4 C 5 6
通过列表创建DataFrame还有另一种方式,演示代码如下:
1 import pandas as pd
2 a = pd.DataFrame() # 创建一个空DataFrame
3 date = [1, 3, 5]
4 score = [2, 4, 6]
5 a[‘date’] = date6
a[‘score’] = score
7 print(a)
注意要保证列表date和score的长度一致,否则会报错。运行结果如下:
1 date score
2 0 1 2
3 1 3 4
4 2 5 6
(2)通过字典创建DataFrame
除了通过列表创建DataFrame,还可以通过字典创建DataFrame,默认以字典的键名作为列索引,演示代码如下:
1 import pandas as pd2 b = pd.DataFrame({‘a’: [1, 3, 5], ‘b’: [2, 4, 6]}, index=[‘x’, ‘y’, ‘z’])3 print(b)
运行结果如下,可以看到列索引是字典的键名。
1 a b
2 x 1 2
3 y 3 4
4 z 5 6
如果想以字典的键名作为行索引,可以用from_dict()函数将字典转换成DataFrame,同时设置参数orient的值为’index’。演示代码如下:
1 import pandas as pd2 c = pd.DataFrame.from_dict({‘a’: [1, 3, 5], ‘b’: [2, 4, 6]}, orient= ‘index’)3 print(c)
参数orient用于指定以字典的键名作为列索引还是行索引,默认值为’columns’,即以字典的键名作为列索引,如果设置成’index’,则表示以字典的键名作为行索引。运行结果如下:
1 0 1 2
2 a 1 3 5
3 b 2 4 6
(3)通过二维数组创建DataFrame
在NumPy模块创建的二维数组的基础上,也可以创建DataFrame。这里以3.4.2节中创建的二维数组为基础,创建一个3行4列的DataFrame,代码如下:
1 import numpy as np2 import pandas as pd3 a = np.arange(12).reshape(3, 4)4 b = pd.DataFrame(a, index=[1, 2, 3], columns=[‘A’, ‘B’, ‘C’, ‘D’])5 print(b)
运行结果如下:
1 A B C D
2 1 0 1 2 3
3 2 4 5 6 7
4 3 8 9 10 11
DataFrame索引的修改
修改行索引和列索引用得相对较少,这里只做简单介绍。
通过设置index.name属性的值可以修改行索引那一列的名称,演示代码如下:
1 import pandas as pd
2 a = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns = [‘date’, ‘score’], index = [‘A’, ‘B’, ‘C’])
3 a.index.name = ‘公司’
4 print(a)
运行结果如下:
1 date score
2 公司
3 A 1 2
4 B 3 4
5 C 5 6
如果想重命名索引,可以使用rename()函数,在上述4行代码的第3行代码后面输入如下代码:
1 a = a.rename(index={‘A’:’万科’, ‘B’:’阿里’, ‘C’:’百度’}, columns= {‘date’:’日期’, ‘score’:’分数’})
需要注意的是,rename()函数会用新索引名创建一个新的DataFrame,并不会改变a的内容,所以这里将重命名索引之后得到的新DataFrame赋给a,以便在后续代码中使用。也可以通过设置参数inplace为True来一步到位地完成索引的重命名,代码如下:
1 a.rename(index={‘A’:’万科’, ‘B’:’阿里’, ‘C’:’百度’}, columns= {‘date’:’日期’, ‘score’:’分数’}, inplace=True)
运行结果如下:
1 日期 分数
2 公司
3 万科 1 2
4 阿里 3 4
5 百度 5 6
如果想将行索引转换为常规列,可以用reset_index()函数重置索引,代码如下。同样需要将操作结果重新赋给a,或者在reset_index()函数里设置参数inplace为True。
1 a = a.reset_index()
运行后行索引将被重置为数字序号,原行索引变成新的一列,a的打印输出结果如下:
1 公司 日期 分数
2 0 万科 1 2
3 1 阿里 3 4
4 2 百度 5 6
如果想把常规列转换为行索引,例如,将“日期”列转换为行索引,可以使用如下代码:
1 a = a.set_index(‘日期’) # 或者直接写a.set_index(‘日期’, inplace=True)
此时a的打印输出结果如下:
1 公司 分数
2 日期
3 1 万科 2
4 3 阿里 4
5 5 百度 6
二、文件的读取和写入
通过pandas模块可以从多种格式的数据文件中读取数据,也可以将处理后的数据写入这些文件中。本节以Excel工作簿和CSV文件的读取和写入为例讲解具体方法。
文件读取
以下代码可以读取名为“data.xlsx”的工作簿中的数据:
1 import pandas as pd
2 data = pd.read_excel(‘data.xlsx’)
第2行代码中为read_excel()函数设置的文件路径参数是相对路径,即代码文件所在的路径,也可以设置成绝对路径。read_excel()函数还有其他参数,这里简单介绍几个常用参数:
·sheetname用于指定工作表,可以是工作表名称,也可以是数字(默认为0,即第1个工作表)。
·encoding用于指定文件的编码方式,一般设置为UTF-8或GBK编码,以避免中文乱码。
·index_col用于设置索引列。
例如,要以UTF-8编码方式读取工作簿“data.xlsx”的第1个工作表,则可将第2行代码修改为如下代码:
1 data = pd.read_excel(‘data.xlsx’, sheetname=0, encoding=’utf-8′)
除了读取Excel工作簿,pandas模块还可以读取CSV文件。CSV文件本质上是一个文本文件,它仅存储数据,不能像Excel工作簿那样存储格式、公式、宏等信息,所以所占存储空间通常较小。CSV文件一般用逗号分隔一系列值,既可以用Excel打开,也可以用文本编辑器(如“记事本”)打开。
以下代码用于读取CSV文件:
1 data = pd.read_csv(‘data.csv’)
read_csv()函数的常用参数简单介绍如下:
·delimiter用于指定CSV文件的数据分隔符,默认为逗号。
·encoding用于指定文件的编码方式,一般设置为UTF-8或GBK编码,以避免中文乱码。
·index_col用于设置索引列。
例如,要以UTF-8编码方式读取CSV文件“data.csv”,以逗号作为数据的分隔符,则可编写如下代码:
1 data = pd.read_csv(‘data.csv’, delimiter=’,’, encoding=’utf-8′)
文件写入
以下代码可以将数据写入工作簿:
1 import pandas as pd2 data = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=[‘A列’, ‘B列’]) # 创建一个DataFrame3 data.to_excel(‘data.xlsx’) # 将DataFrame中的数据写入工作簿
第3行代码中的文件存储路径使用的是相对路径,可以根据需要写成绝对路径。运行之后将在代码文件所在的文件夹生成一个名为“data.xlsx”的工作簿,打开工作簿可看到如下图所示的文件内容。
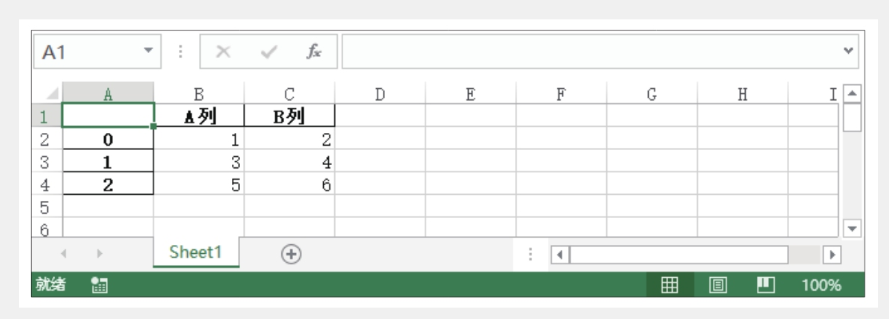
上图中,行索引信息被存储在工作表的第1列中,如果想在写入数据时不保留行索引信息,可以设置to_excel()函数的参数。该函数的常用参数有:
·sheetname用于指定工作表名称。
·index用于指定是否写入行索引信息,默认为True,即将行索引信息存储在输出文件的第1列;若设置为False,则忽略行索引信息。
·columns用于指定要写入的列。
·encoding用于指定编码方式。
例如,要将data中的A列数据写入工作簿并忽略行索引信息,可编写如下代码:
1 data.to_excel(‘data.xlsx’, columns=[‘A列’], index=False)
通过类似的方式,可以将data中的数据写入CSV文件,代码如下:
1 data.to_csv(‘data.csv’)
和to_excel()函数类似,to_csv()函数也可以设置index、columns、encoding等参数。
三、数据的选取和处理
创建了DataFrame之后,就可以对其中的数据进行进一步的选取和处理,本节就来讲解相应的方法。这些知识点在后面的章节中应用较多,需要好好掌握。
首先创建一个3行3列的DataFrame用于演示,行索引设定为r1、r2、r3,列索引设定为c1、c2、c3,代码如下:
1 data = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=[‘r1’, ‘r2’, ‘r3’], columns=[‘c1’, ‘c2’, ‘c3’])
也可以用3.5.1节中介绍的方法,通过二维数组创建DataFrame。这里以数字1为起点,数字10为终点(终点取不到),生成1~9共9个整数,作为DataFrame中的数据,代码如下:
1 data = pd.DataFrame(np.arange(1, 10).reshape(3, 3), index=[‘r1’, ‘r2’, ‘r3’], columns=[‘c1’, ‘c2’, ‘c3’])
两种方法得到的data是一样的,打印输出结果如下:
1 c1 c2 c3
2 r1 1 2 3
3 r2 4 5 6
4 r3 7 8 9
接下来就用这个data讲解数据的选取、筛选、排序、运算与删除等知识点。\
数据的选取
(1)按列选取数据
先从简单的选取单列数据入手,代码如下:
1 a = data[‘c1’]
a的打印输出结果如下:
1 r1 1
2 r2 4
3 r3 7
4 Name: c1, dtype: int64
可以看到,选取的数据不包含列索引信息,这是因为通过data[‘c1’]选取一列时返回的是一个一维的Series类型的数据。通过如下代码可以返回一个二维的表格数据。
1 b = data[[‘c1’]]
b的打印输出结果如下:
1 c1
2 r1 1
3 r2 4
4 r3 7
如果要选取多列,则需在中括号[]中以列表的形式给出列索引。例如,选取c1和c3列的代码如下:
1 c = data[[‘c1’, ‘c3’]]
这里的data[[‘c1′,’c3’]]不能写成data[‘c1′,’c3’]。
c的打印输出结果如下:
1 c1 c3
2 r1 1 3
3 r2 4 6
4 r3 7 9
(2)按行选取数据
可以根据行序号来选取数据,代码如下:
1 # 选取第2~3行的数据,注意序号从0开始,左闭右开2 a = data[1:3]
a的打印输出结果如下:
1 c1 c2 c32 r2 4 5 63 r3 7 8 9
但是data[1:3]可能会引起混淆报错,所以pandas模块的官方文档推荐使用iloc方法来根据行序号选取数据,这样更直观,代码如下:
1 b = data.iloc[1:3]
如果要选取单行,就必须用iloc方法。例如,选取倒数第1行,代码如下:
1 c = data.iloc[-1]
此时如果使用data[-1],则Python可能会认为-1是列名,导致混淆报错。
除了根据行序号选取数据外,还可以使用loc方法根据行的名称来选取数据,代码如下:
1 d = data.loc[[‘r2’, ‘r3’]]
如果行数很多,可以用head()函数选取前5行数据,代码如下:
1 e = data.head()
这里因为data只有3行数据,所以用head()函数会选取全部数据。如果只想选取前两行数据,可以写成data.head(2)。
(3)按区块选取数据
如果想选取某几行的某几列数据,例如,选取c1和c3列的前两行数据,代码如下:
1 a = data[[‘c1’, ‘c3’]][0:2] # 也可写成data[0:2][[‘c1’, ‘c3’]]
其实就是把前面介绍的按行和按列选取数据的方法进行了整合,a的打印输出结果如下:
1 c1 c32 r1 1 33 r2 4 6
在实战中选取区块数据时,通常先用iloc方法选取行,再选取列,代码如下:
1 b = data.iloc[0:2][[‘c1’, ‘c3’]]
两种方法的选取效果是一样的,但第二种方法逻辑更清晰,代码不容易混淆,它也是pandas模块的官方文档推荐的方法。
如果要选取单个数据,该方法就更有优势。例如,选取c3列第1行的数据,不能写成data[‘c3’][0]或data[0][‘c3’],而要先用iloc[0]选取第1行,再选取c3列,代码如下:
1 c = data.iloc[0][‘c3’]
也可以使用iloc和loc方法同时选取行和列,代码如下:
1 d = data.loc[[‘r1’, ‘r2’], [‘c1’, ‘c3’]]2 e = data.iloc[0:2, [0, 2]]
需要注意的是,loc方法使用字符串作为索引,iloc方法使用数字作为索引。有个简单的记忆方法:loc是location(定位、位置)的缩写,所以是用字符串作为索引;iloc中多了一个字母i,而i又经常代表数字,所以是用数字作为索引。
d和e的打印输出结果如下:
1 c1 c3
2 r1 1 3
3 r2 4 6
选取区域数据还可以用ix方法,它的索引不像loc或iloc必须为字符串或数字,代码如下:
1 f = data.ix[0:2, [‘c1’, ‘c3’]]
其操作逻辑和效果与data.iloc[0:2][[‘c1′,’c3’]]一样,但pandas模块的官方文档目前已经不推荐使用ix方法。
数据的筛选
通过在中括号里设定筛选条件可以过滤行。例如,筛选c1列中数字大于1的行,代码如下:
1 a = data[data[‘c1’] > 1]
a的打印输出结果如下:
1 c1 c2 c3
2 r2 4 5 6
3 r3 7 8 9
如果有多个筛选条件,可以用“&”(表示“且”)或“|”(表示“或”)连接起来。例如,筛选c1列中数字大于1且c2列中数字等于5的行,代码如下。注意要用小括号将筛选条件括起来。
1 b = data[(data[‘c1’] > 1) & (data[‘c2’] == 5)]
b的打印输出结果如下:
1 c1 c2 c3
2 r2 4 5 6
数据的排序
使用sort_values()函数可以按列对数据进行排序。例如,将data按c2列进行降序排序的代码如下:
1 a = data.sort_values(by=’c2′, ascending=False)
参数by用于指定按哪一列来排序;参数ascending(“上升”的意思)默认值为True,表示升序排序,若设置为False则表示降序排序。a的打印输出结果如下:
1 c1 c2 c3
2 r3 7 8 9
3 r2 4 5 6
4 r1 1 2 3
使用sort_index()函数可以按行索引进行排序。例如,按行索引进行升序排序的代码如下:
1 a = a.sort_index()
运行上述代码后,前面按c2列降序排序后生成的a的行索引又变成r1、r2、r3的升序排序形式了。sort_index()函数同样也可以通过设置参数ascending为False来进行降序排序。
数据的运算
通过数据运算可以基于已有的列生成新的一列,演示代码如下:
1 data[‘c4’] = data[‘c3’] – data[‘c1’]
data的打印输出结果如下:
1 c1 c2 c3 c4
2 r1 1 2 3 2
3 r2 4 5 6 2
4 r3 7 8 9 2
数据的删除
使用drop()函数可以删除DataFrame中的指定数据,该函数的常用参数简单介绍如下:
·index用于指定要删除的行。
·columns用于指定要删除的列。
·inplace默认值为False,表示该删除操作不改变原DataFrame,而是返回一个执行删除操作后的新DataFrame,如果设置为True,则会直接在原DataFrame中进行删除操作。
例如,删除data中的c1列数据的代码如下:
1 a = data.drop(columns=’c1′)
删除多列数据时,要以列表的形式给出列索引,例如,删除c1和c3列的代码如下:
1 b = data.drop(columns=[‘c1’, ‘c3’])
删除多行数据时,同样要以列表的形式给出行索引,例如,删除第1行和第3行的代码如下:
1 c = data.drop(index=[‘r1’, ‘r3’])
需要注意的是,给出行索引时要输入行索引名称而不是数字序号,除非行索引名称本来就是数字。
上述这些演示代码将删除数据后的新DataFrame赋给新的变量,并不会改变原DataFrame(data)的结构,如果想改变原DataFrame(data)的结构,可以设置参数inplace为True,演示代码如下:
1 data.drop(index=[‘r1’, ‘r3’], inplace=True)
四、数据表的拼接
pandas模块还提供了一些高级功能,其中的数据合并与重塑功能为两个数据表的拼接提供了极大的便利,主要涉及merge()函数、concat()函数、append()函数。其中merge()函数用得较多。下面通过一个简单的例子演示这3个函数的用法。
假设用如下代码创建了两个DataFrame数据表,现在需要将它们合并:
1 import pandas as pd
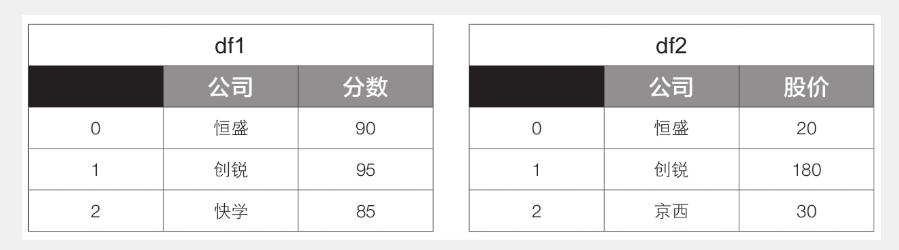
2 df1 = pd.DataFrame({‘公司’: [‘恒盛’, ‘创锐’, ‘快学’], ‘分数’: [90, 95, 85]})
3 df2 = pd.DataFrame({‘公司’: [‘恒盛’, ‘创锐’, ‘京西’], ‘股价’: [20, 180, 30]})
上述代码得到的df1和df2的内容见下表。
merge()函数
merge()函数可以根据一个或多个同名的列将不同数据表中的行连接起来,演示代码如下:
1 df3 = pd.merge(df1, df2)
运行后df3的内容见下表。
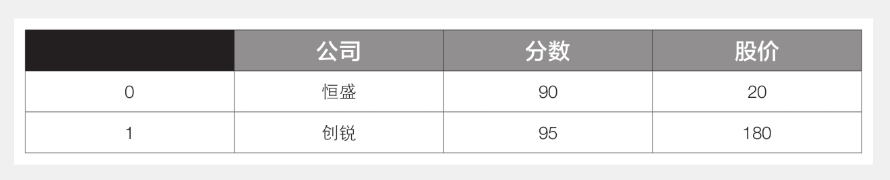
可以看到,merge()函数直接根据相同的列名(“公司”列)对两个数据表进行了合并,而且默认选取的是两个表共有的列内容(’恒盛’、’创锐’)。如果同名的列不止一个,可以通过设置参数on指定按照哪一列进行合并,代码如下:
1 df3 = pd.merge(df1, df2, on=’公司’)
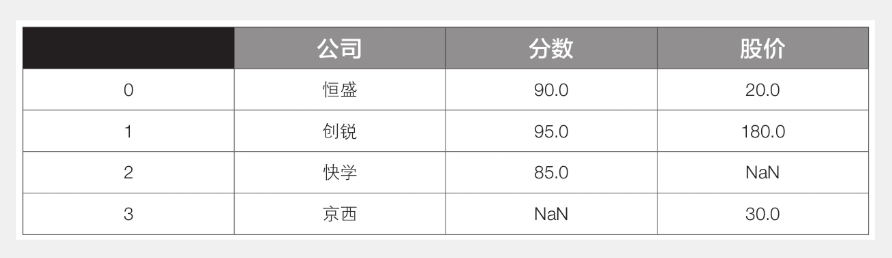
默认的合并方式其实是取交集(inner连接),即选取两个表共有的内容。如果想取并集(outer连接),即选取两个表所有的内容,可以设置参数how,代码如下:
1 df3 = pd.merge(df1, df2, how=’outer’)
运行后df3的内容见下表,可以看到所有数据都在,原来没有的内容则用空值NaN填充。
如果想保留左表(df1)的全部内容,而对右表(df2)不太在意,可以将参数how设置为’left’,代码如下:
1 df3 = pd.merge(df1, df2, how=’left’)
此时df3的内容见下表,完整保留了df1的内容(’恒盛’、’创锐’、’快学’)。
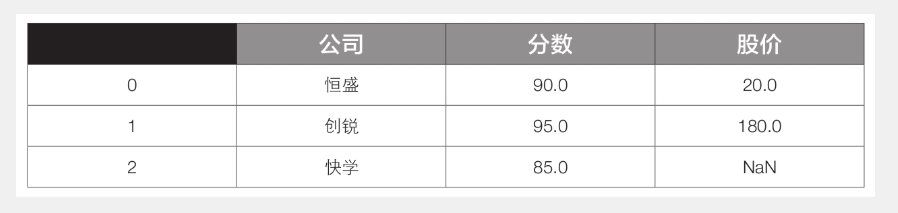
同理,如果想保留右表(df2)的全部内容,而不太在意左表(df1),可以将参数how设置为’right’。
如果想按照行索引进行合并,可以设置参数left_index和right_index,代码如下:
1 df3 = pd.merge(df1, df2, left_index=True, right_index=True)
此时df3的内容见下表,两个表按照它们的行索引进行了合并。
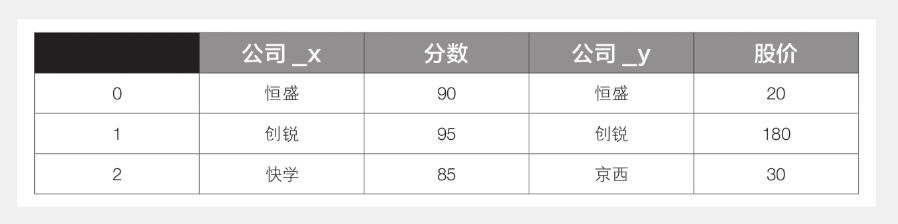
concat()函数
concat()函数使用全连接(UNION ALL)方式完成拼接,它不需要对齐,而是直接进行合并,即不需要两个表有相同的列或索引,只是把数据整合到一起。因此,该函数没有参数how和on,而是用参数axis指定连接的轴向。该参数默认值为0,指按行方向连接(纵向拼接)。代码如下:
1 df3 = pd.concat([df1, df2]) # 或者写成df3 = pd.concat([df1, df2], axis=0)
此时df3的内容见下表。
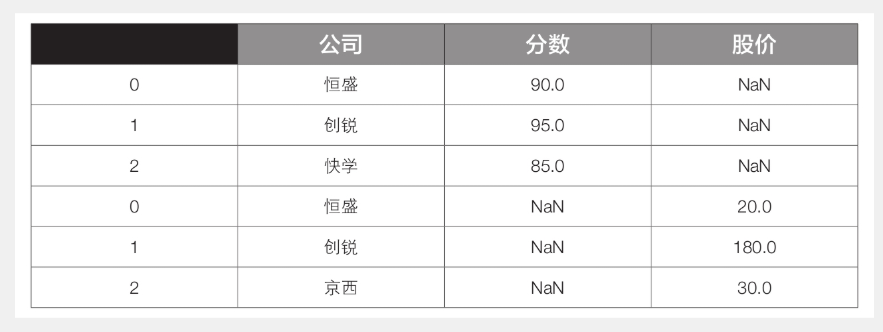
此时的行索引为原来两个表各自的索引,如果想重置索引,可以使用3.5.1节讲过的reset_index()函数,或者在concat()函数中设置参数ignore_index为True来忽略原有索引,生成新的数字序列作为索引,代码如下:
1 df3 = pd.concat([df1, df2], ignore_index=True)
如果想按列方向连接,即横向拼接,可以设置参数axis为1。代码如下:
1 df3 = pd.concat([df1, df2], axis=1)
此时df3的内容见下表。
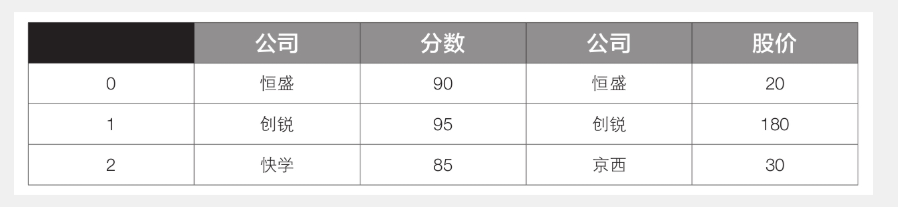
append()函数
append()函数可以看成concat()函数的简化版,效果和pd.concat([df1,df2])类似,实现的也是纵向拼接,代码如下:
1 df3 = df1.append(df2)
append()函数还有一个和列表的append()函数一样的用途——新增元素,代码如下:
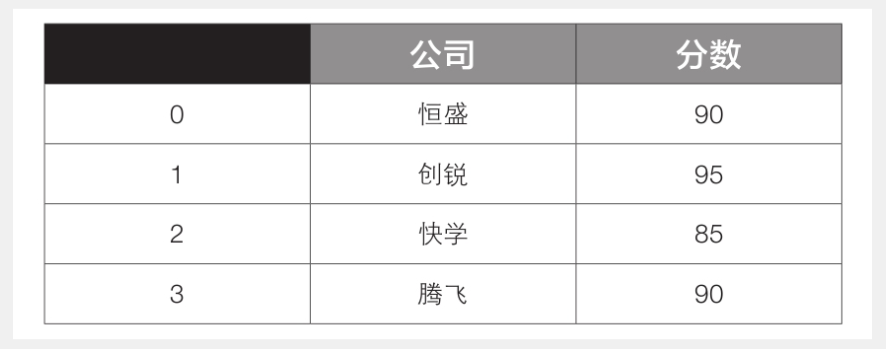
1 df3 = df1.append({‘公司’: ‘腾飞’, ‘分数’: ’90’}, ignore_index=True)
这里一定要设置参数ignore_index为True来忽略原索引,否则会报错。生成的df3的内容见右表。
以上即是pandas模块的基础知识,在后面的章节中还将通过多个案例对这个模块的功能进行详细介绍。
未经允许不得转载:陈海飞博客 » python数据导入和整理模块-pandas